
Pipes are one of Linux’s and Unix-like operating systems’ most valuable command-line capabilities. They are utilized in a variety of applications. If you look at any Linux command-line article, you’ll notice that pipes appear frequently.
The vertical bar symbol | denotes a pipe. Because of the pipe, you can take the output from one command and feed it to another command as input.
As a result, the output of one command can be used as the input for another, and the output of that command can be used as the input for the next command, and so on.
So you’re not limited to a single piped command. You can stack them as many times as you like.
In other words, a pipe is a form of redirection used in Linux to send the output of one program to another program for further processing. Pipes allow you to do operations that the shell does not support out of the box.
The syntax for the pipe or unnamed pipe command is the | character between any two commands:
command1 | command2 | ... | commandNCode language: Bash (bash)How Does a Pipe Work in Linux
To see how pipe works, let’s look at the examples below. We have a directory full of many different types of files, and we want to know how many files of a particular kind are in it.
So we can get a list of files easily using the ls command:
ls -lCode language: Bash (bash)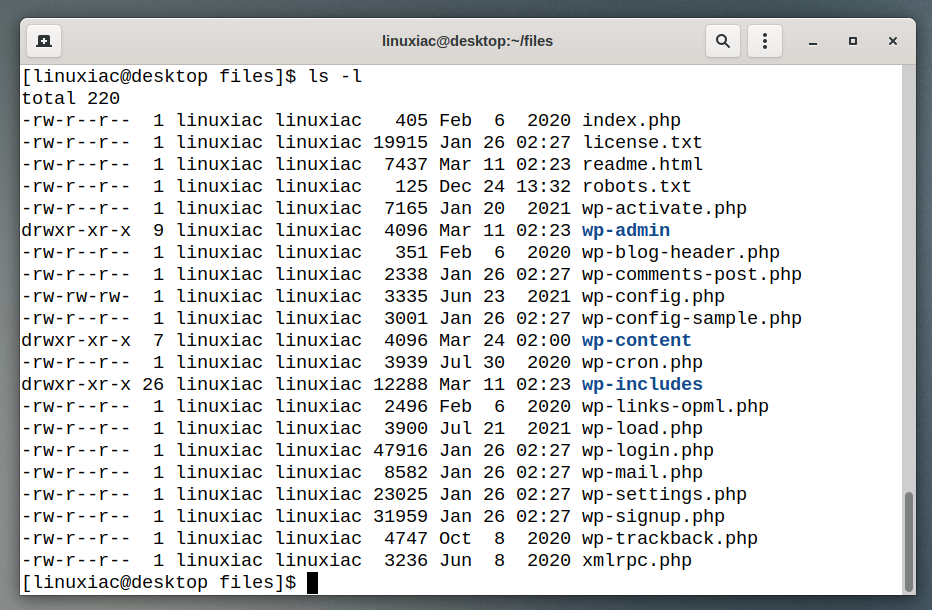
We’ll use grep to separate the types of files we’re looking for. For example, we seek files with the word “txt” in their name or as a file extension.
We will use the special shell character | to direct ls‘ output to grep.
ls | grep txtCode language: Bash (bash)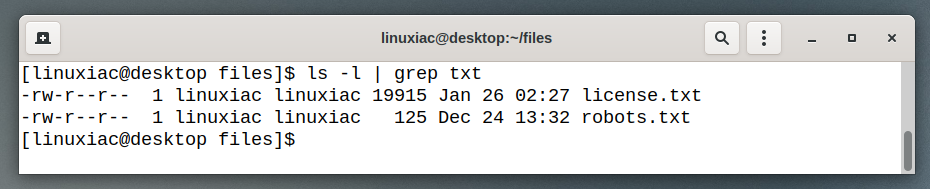
As you can see from the image above, the ls command output was not sent to the terminal window.
Therefore, the result is not displayed on the screen but is redirected to the input of the grep command. The output we see above comes from grep, the last command in this chain.
Now, let’s start extending our chain. We can count files “txt” by adding the wc command to the chain. We will use the -l option (number of lines) with wc.
ls | grep txt | wc -lCode language: Bash (bash)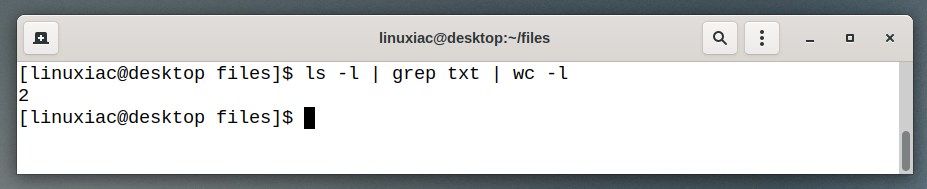
In the example above, grep is no longer the last command in the chain, so we do not see its output. Instead, the output of grep is fed into the wc command.
The result that we see in the terminal window comes from wc. It reports two files, “txt” in the directory.
What Is a Named Pipe in Linux?
As the name itself suggests, these are pipes with names. One of the key differences between regular pipes and& named pipes is that named pipes have a presence in the file system. That is, they show up like files.
The named pipe in Linux is a method for passing information from one computer process to another using a pipe given a specific name. Named pipes are also known as FIFO, which stands for First In, First Out.
You can create a named pipe using the mkfifo command. For example:
<code>mkfifo mypipe</code>Code language: Bash (bash)You can tell if a file is a named pipe by the p bit in the file permissions section.
ls -l mypipeCode language: Bash (bash)prw-r--r-- 1 root root 0 Mar 20 12:58 mypipeCode language: CSS (css)The named pipes are files on the file system itself. Unlike a standard pipe, a named pipe is accessed as part of the filesystem, just like any other file type.
The named pipe content resides in memory rather than being written to disk. So, it is passed only when both ends of the pipe have been opened. You can write to a pipe multiple times before it is iYoud at the other end and read.
Using named pipes lets you establish a process in which one process writes to a pipe, and another reads from a pipe without much concern about trying to time or carefully orchestrate their interaction.
Let’s look at the examples below to see how named pipes work. First, create our named pipe:
mkfifo mypipeCode language: Bash (bash)Now, let’s consume messages with this pipe.
tail -f mypipeCode language: Bash (bash)Then, open another terminal window and write a message to this pipe:
echo "hi" >> mypipeCode language: Bash (bash)Now, in the first window, you can see the “hi” printed out:
tail -f mypipe
hiCode language: Bash (bash)Because it is a pipe and the message has been consumed, if we check the file size, you can see it is still 0:
ls -l mypipeCode language: Bash (bash)prw-r--r-- 1 root root 0 Mar 20 14:11 mypipeCode language: CSS (css)Since a named pipe is just a Linux file, we can use the rm command to remove one. Therefore, to remove the pipe we created in the previous examples, we would run:
rm mypipeCode language: Bash (bash)When to Use Regular or Named Pipes
Using a regular pipe instead of a named pipe in Linux depends on the characteristics we’re looking for. Some can be persistence, two-way communication, having a filename, creating a filter, and restricting access permissions.
For example, using an anonymous pipe seems the most appropriate option if we want to filter a command’s output multiple times. On the other hand, if we need a filename and don’t want to store data on disk, we’re looking for a named pipe.
In conclusion, the next time you work with commands in the Linux terminal and find yourself moving data between commands, use pipes – they will make the process quick and easy.
Conclusion
This article showed you the versatility of pipes when used in Linux commands. Although relatively simple, it can resolve a wide range of complicated queries.
For more about the pipe command in Linux, consult its manual page.





Hi Bobby. I found a mistake in the articule: There is "tail -f pipe1" but should be "tail -f mypipe". BTW, Thank you for jour good job!
Hey, Haflinger,
Thanks for your observation. Corrected!